





Table of Contents
Believe it or not, it was just six months ago that news of Google’s leaked documents came to light. Although the findings didn’t tell experienced SEOs much we didn’t already suspect, much of it (notably the use of clickstream and Chrome data) was nice confirmation of several things the search engine had previously denied was used for organic search rankings.
The leaked documents, “ClickiLeaks”, as we like to call it, inevitably caused much furore in the industry which, let’s face it, doesn’t need much encouragement. I’m still not 100% sure on exactly how these events unfolded and this article is absolutely open to some fact-checking, but half a year later this is how I believe things to have unfolded.
Estimated Timeline of ClickiLeaks Events
March 27, 2024
The leak was first discovered when Google’s internal API documentation was exposed publicly via GitHub. The error was later patched, but not before copies of the documentation had circulated.
Undefined Date
Dan Petrovic received the documentation and later shared it with Mike King. He verified the details independently and began investigating the potential impact.
May 5, 2024
Rand Fishkin then obtained the documents from an anonymous source around early May 2024 (later revealed to be Erfan Azimi), after which he published his findings on SparkToro, providing transparency about the documents’ authenticity.
May 7, 2024
Google patches the exposed repositories.
May 24, 2024
Rand Fishkin and Mike King verify the authenticity of the documents.
May 27, 2024
Rand Fishkin publishes his initial findings on SparkToro.
May 28, 2024
The anonymous source, Erfan Azimi, reveals his identity.
Who Is Erfan Azimi?
Erfan Azimi is CEO of EA Eagle Digital and played a crucial role in the exposure of Google’s search documentation leak. According to several reports, Azimi was the one who initially discovered the documents when they were inadvertently made public on GitHub in March 2024.
Recognising the significance of the data, he decided to share this information with Rand Fishkin of SparkToro, who in turn validated the leak and later collaborated with Mike King of iPullRank for further analysis and dissemination.
On May 28th, 2024, he publicly revealed himself as the source behind the leak.
Google Leak Perspectives From 3 Of The Best
The remainder of this article rounds up perspectives from three prominent figures in the SEO industry: Mike King, Dan Petrovic, and Rand Fishkin, providing a summary of the leak and its implications. These guys were instrumental to ClickiLeaks in one way or another and as three of the most reputable voices in the sector, their interpretation is crucial.
However, it does have to be noted, that other than the information from the aforementioned experts, some of this information has been taken from elsewhere on the web and should be treated with caution. If you have a correction or some insight to add, please do reach out as I am definitely not an authority on the matter.
The Leak Unveiled
The leak surfaced in early May 2024 when the anonymous source (at the time) shared a series of Google’s internal API documentation with Rand Fishkin. The documents, which were authenticated by several ex-Google employees, revealed detailed information about Google’s search operations and contradict many public statements made by the company over the years.
Key Points from Rand Fishkin
NavBoost and User Signals
The documents confirmed that Google uses a system called NavBoost to collect and analyze user click data. This system has been in place since at least 2005 and helps Google determine the quality and relevance of search results based on user interactions.
Chrome Browser Data
Google also leverages clickstream data from its Chrome browser to inform search rankings. This includes data on user clicks, session durations, and other engagement metrics, contradicting Google’s public denials of using such data.
Whitelists for Specific Queries
The leak revealed that Google maintains whitelists for certain types of queries, such as those related to travel, COVID-19, and elections, ensuring only trusted sources appear in search results for these critical topics.
Quality Rater Feedback
Google’s quality raters, through the EWOK platform, provide data that directly influences search rankings, contradicting Google’s claims that rater feedback is only used for training purposes.
Insights from Mike King
Mike King’s detailed review of the leak, available at the iPullRank website, offered additional insights:
Content Warehouse API
The leaked documentation came from Google’s Content Warehouse API, which details how Google stores and processes data related to web content, links, and user interactions.
Ranking Factors and Data Storage
The documents provide extensive information about the features Google considers, such as user clicks, content quality, and link data, highlighting the importance of a holistic approach to SEO.
Google’s Internal Processes
The leak sheds light on Google’s internal processes for evaluating and ranking content, including the use of deprecated features and ongoing updates to their systems.
Perspectives from Dan Petrovic
Dan was the individual who initially discovered the exposed repo and spent a great deal of time studying it. Although he has been incredibly modest and had no desire to call Google out, as close friends of Rand Fishkin and Mike King, he realised they were the most trustworthy and reliable people to disseminate this information.
Petrovic views the leak as a strategic asset that, while initially valuable, becomes compromised once public. He discussed his attempts to report the exposed repository to Google discreetly, hoping to prevent major changes that could render the information useless.
Long Term Implications for SEO
The leak could potentially have significant impact on the industry. Six months later, the algorithm is more unpredictable than ever and life has become more challenging for Google representatives on social media and other platforms.
Focus on User Experience
The emphasis on user signals and engagement metrics reaffirms the need to prioritise user experience. Websites should aim to engage users effectively, ensuring longer sessions and positive interactions.
Holistic SEO Strategies
Given the broad range of factors considered by Google, SEO strategies should be holistic, integrating content quality, technical SEO, and user engagement.
Be Ready to Adapt To Huge Changes in SEO
SEO professionals must stay agile and ready to adapt to changes in Google’s algorithms. We have discussed this recently via our guide to future-proofing your SEO career in 2025, where adaptation and versatility will be paramount.
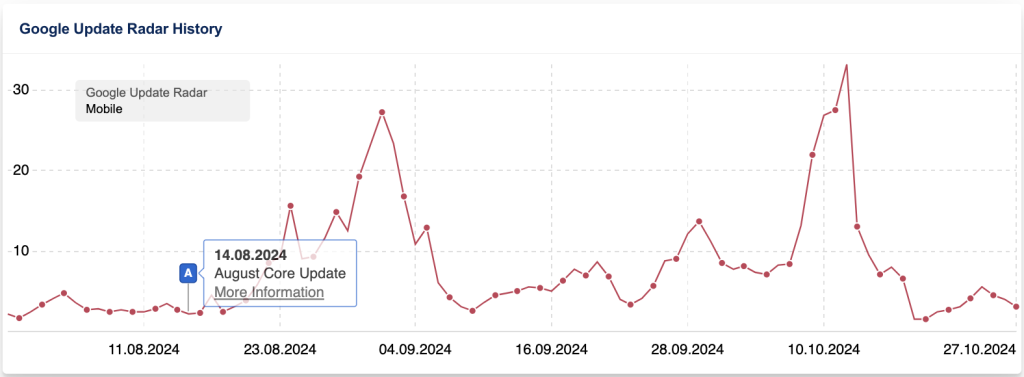
The leak suggested that Google may implement significant updates in response to the exposed information, which may explain the unprecedented volatility in the algorithms since the leak.
There is much going on that we aren’t told about, entirely separate from official guidelines and algorithm updates. The onus is on SEOs to conduct independent testing and reach their own conclusions instead of relying solely on Google’s statements.
Those involved in disseminating this data should be applauded, whether they believe it was the right decision or not. Given the massive investment in SEO globally, transparency from search engines is crucial, as the recent Antitrust case highlights, confidence in that transparency is at an all-time low.
